Sidekiq Tuning Small Mastodon Servers
[Updated: ]
This configuration is based on sunny.garden which has comfortably served between 500 and 1000 users from a single server with 4 CPU cores, and 8 GB of RAM.
It should be applicable up to around 2000 users by increasing CPU and RAM if required, but I don’t know how much farther beyond that it will get you.
Summary
Run one scheduler sidekiq process using sidekiq -c 5 -q scheduler,1 -q mailers,1 and one worker process using sidekiq -c 5 -q default,8 -q push,6 -q ingress,4 -q pull,1 to start with, and then increase the number of worker processes as needed.
For details on how and why to do that, read on…
Step By Step
As part of Mastodon installation instructions, you are asked to copy the files mastodon-sidekiq.service, mastodon-streaming.service, and mastodon-web.service to /etc/systemd/system, and editing these files in /etc/systemd/system is how you tune the associated Mastodon services.
The default sidekiq service file is:
mastodon-sidekiq.servicewhich runssidekiq -c 25
The command line sidekiq -c 25 hides the fact that sidekiq actually processes 6 different queues which handle different kinds of jobs: default, push, pull, ingress, mailers, and scheduler.
Step 1 - Initial Setup
My recommendation is to copy the default service file to two separate service files, one which runs only the scheduler and mailers queues, and another which runs all of the rest which I’ll refer to as a worker process.
For example:
mastodon-sidekiq-scheduler.servicerunssidekiq -c 5 -q scheduler,1 -q mailers,1mastodon-sidekiq-1.servicewhich runssidekiq -c 5 -q default,8 -q push,6 -q ingress,4 -q pull,1
Both should have DB_POOL set to 5 to match sidekiq -c 5. Be sure to update the description at the top of each file to match the filename for clarity’s sake.
Any time you make changes to the .service files remember to run:
systemctl daemon-reload
Now disable the default service file:
systemctl disable --now mastodon-sidekiq
And enable the two new service files:
systemctl enable --now mastodon-sidekiq-scheduler mastodon-sidekiq-1
Once you’ve tested everything is working you can delete the default mastodon-sidekiq.service to make sure that it doesn’t get accidentally started again. Don’t forget to systemctl daemon-reload again.
Weighted Queues: What do those numbers mean after the queue names?
The numbers after the queue names are the relative weights or priorities of the different queues. When using weighted queues, a sidekiq process will continually choose jobs from all of its queues, but will choose higher weighted jobs more often. A weight of 8 will be chosen twice as often as a weight of 4, and so on.
This prevents any of the queues from stalling while waiting for the other queues to be cleared, but also ensures that higher priority jobs happen sooner.
A mistake that people (including me) sometimes make when creating a custom sidekiq config is listing the queues without weights, which causes sidekiq to use strict ordering.
If you list the queues without weights, eg:
sidekiq -c 5 -q default -q push -q ingress -q pull
…then all of the queues would be processed in order, sidekiq will attempt to finish all of the default jobs first, and then all of the push jobs, and so on. If your server is under heavy load with new jobs constantly being created in all of the queues, this can lead to the queues at the end of the list never getting processed, and piling up for hours.
You might try creating individual worker processes to handle each queue so that there’s always a process available to handle that queue, but this also wastes that process, leaving it idle, in the case where there are only jobs in other queues that need handling.
Using weighted queues ensures that:
- All queues are being processed all of the time
- Higher priority jobs are still handled sooner
- All of your workers are always running jobs, and not sitting idle when there are jobs waiting for processing.
The default configuration of sidekiq -c 25 is actually using weighted queues as well although it’s not obvious. When no queues are specified on the command line, the default config (which includes weights) gets loaded from config/sidekiq.yml.
Step 2 - Scaling Up
If your server only has a dozen or so active users, that’s it, you’re done for now!
As your user count increases to 100 or 200 users, and activity on your server increases accordingly, you might need to add more sidekiq workers to handle the additional jobs.
I used to estimate scaling requirements based solely on user count, but I think a much better guide is the number of jobs your server is handling per day, which is highly dependant on the overall activity level of the connected fediverse.
Take a look at the sidekiq Dashboard and check the History chart to see how many jobs are being processed by your server per day:
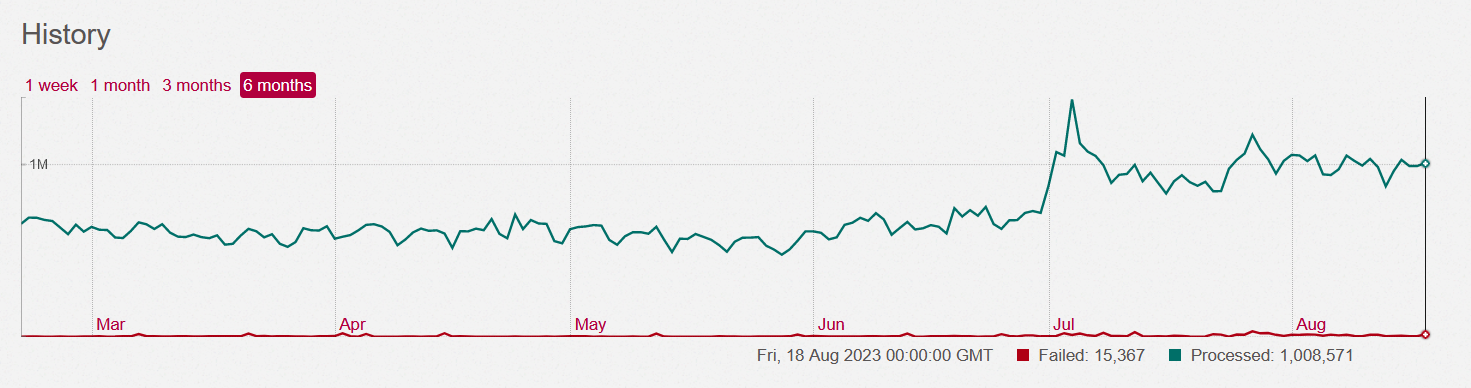
While sunny.garden was sitting around 300 users and 600k jobs/day, two sidekiq workers was enough. When load spiked over 1 million jobs/day in July, a third worker process was needed to keep up.
Based on my and other admins’ experience, a good rule of thumb appears to be:
- 1 worker process (with 5 threads) per 500k jobs/day
To add a new worker process:
- copy
mastodon-sidekiq-1.servicetomastodon-sidekiq-2.serviceand update the description. - run
daemon-reload - run
systemctl enable --now mastodon-sidekiq-2
Up to about 500k jobs/day one worker is probably enough, add a second when you reach 500k, a third when you reach 1M, and so on.
Don’t run more processes than you have CPU cores or RAM to handle.
If your CPU load or RAM usage are maxed out, you’ll need to upgrade your hardware before adding more workers, otherwise adding workers will just make everything run more slowly.
With 4 CPU cores and 8GB of RAM I can run 2-3 sidekiq worker processes comfortably along with everything else that’s running on the same machine. Each copy may use 0.5 to 1GB RAM depending on activity level.
One nice thing about this setup is that once you’ve created these service files, you can easily turn the additional sidekiq workers on and off by enabling and disabling the individual service files using systemctl, without needing to edit them or reload.
Step 3 - Dealing with Memory Leaks
Unfortunately, the ingress queue leaks memory. Leaks of 1-2 GB per week are typical, and it will just keep leaking until things slow down or start to crash.
If you only have a few users, the leak may be so small that you never need to do anything about it, but the more activity your server processes the more of an issue it will become.
The way I deal with this is simply to restart the sidekiq processes daily using cron:
0 9 * * * systemctl restart mastodon-sidekiq-1
30 9 * * * systemctl restart mastodon-sidekiq-2
0 10 * * * systemctl restart mastodon-sidekiq-3
The restarts are staggered so they don’t all happen at the same moment.
Why not isolate the ingress queue?
Another way to do this would be to isolate the ingress queue in it’s own process, eg:
mastodon-sidekiq-ingress.servicerunssidekiq -c 5 -q ingress
And remove the ingress queue from the other service files.
Now you can restart just the ingress queue by itself without impacting the others.
Alternatively, this setup lets you to monitor the memory use of the ingress queue in isolation, to verify that it is leaking memory over multiple days.
Since I’ve already gone through that process and found that it does indeed leak, I prefer to keep it combined with the other queues to make better use of the resources allocated to sidekiq. A process that only runs a single queue is somewhat wasted if there are jobs waiting to be done, but none of them are in that specific queue.
Sidekiq Rules
Rule: Make sure you are only ever running the scheduler queue from one process at a time.
Make sure you only have one scheduler queue running!!
Rule: DB_POOL and sidekiq -c should always be the same number.
The database pool size is controlled with the DB_POOL environment variable and must be at least the same as the number of threads.
Guideline: sidekiq -c should be 5.
This is my personal recommendation having seen many recommendations to keep this value low, no compelling arguments for any specific higher value at the scale that we’re dealing with, and it makes practical sense to keep the number reasonably low to reduce resource contention.
Are you really sure 5 is the best number?
No, I’m not sure it’s the best, but I am sure it’s sufficient, having run this configuration for months with no issues. If you try and raise this number, you will also start running into other limits like the number of available database connections you have, which is a whole other blog post.
Increasing the total number of threads threads beyond your actual capacity will only make things run more slowly, and increase failures due to timeouts, etc.
So how many threads should we use? … This matches my own experience: on client applications, thread settings of more than 5 have no effect.
Nate Berkopec - https://www.speedshop.co/2017/10/12/appserver.html
The above post is discussing rails apps in general, and puma in particular, not sidekiq; but the concept cited here is general.
You should not always increase the concurrency, but sometimes try to reduce it, and spawn more sidekiq workers on the same queues
@renchap (Mastodon CTO), joinmastodon Discord - 2022-11-24
With 4 servers, I would advise … 2 for sidekiq, with as many sidekiq processes as needed (dont use more than 15-25 threads per sidekiq process)
@renchap (Mastodon CTO), joinmastodon Discord - 2022-12-16
Keep in mind the “15-25” here is a maximum, and aimed at people running multiple servers that do nothing else except run sidekiq.
If you have evidence to suggest that increasing from 5 to some higher number will make things run better (and not just the same) on a server of the scale this page applies to, please let me know.
Guideline: 1 worker process (5 threads) for every 500k jobs/day
A worker process here meaning a sidekiq service file running as discussed above:
sidekiq -c 5 -q default,8 -q push,6 -q ingress,4 -q pull,1
This is based on my own experience, running all of Mastodon on a single server, including nginx, postgresql, elastic search, etc. and appears to be roughly consistent with other admins running similar sized servers.
Further Reading
These links are to official Mastodon sources, but keep in mind they are aimed at scaling to much larger sizes than discussed here.
- Scaling up your server | joinmastodon.org
- Scaling up a Mastodon server to 128K active users | @Gargron
The following resources are based on other admins experiences and may contain advice that contradicts what is presented here, or is aimed at different situations. Thanks to @custodian@ngmx.com for this list of bookmarks: